Open Source
Resistance Is Futile, Or Is It?
If I have seen further it is only by standing
on the shoulders of giants.
Today we stand on each other's feet
(or stomp on each other's toes).
Competition & Cooperation
In many fields of human endeavor there is a tension between the fundamental issues of competition and cooperation. Both serve useful and vital roles – competition driving us to try hard, cooperation allowing us to work together and build on the work of others. Neither, if taken to the extreme, is healthy. Unbridled competition leads to wasteful duplication of effort, counter-productive efforts aimed at harming competitors rather than making progress, and outright unethical behavior. Unlimited cooperation leads to exploitation by others, inequity, laziness, low productivity, and outright unviability. A delicate balance between the two must be struck in order for any society, or industry, to function well in the long term.
The field of computer science feels this tension to an especially high degree, sitting awkwardly between the scientific world, based primarily on cooperation and sharing of knowledge, and the business world, based on competitive forces and thus advocating secrecy, restriction and control of that valuable knowledge.
The gradual rise of open-source software during the past 25 years, and particularly its gain in momentum and public visibility during the past 10 years since the open-sourcing of Netscape, represents a swing back towards the open sharing characteristics of science, away from the prevailing business-oriented model which still dominates today. It is perhaps the most fundamental shift that has ever occurred in the software industry, and does not appear to be a temporary aberration.
Open source also presents a deep and profound challenge to the model of financial viability on which the software industry has historically been based. Nobody in the industry, not even the most extreme open-source advocates, want to see it go the way of the pure sciences, reduced to begging for grants from governments. Yet it remains unclear exactly how open-source software can possibly be financially viable in the long term, given that the code is, by definition, made openly available for free.
I'm often asked what I think about the open-source movement. Some of the people who know me best think I'm strongly in favor of it, mainly because I've released some of my work as open source, and also because I've published research, which includes publishing the algorithms, essentially putting them into the public domain. Other people who know me well think I'm strongly against open source, because my largest and most important work has been, and remains, commercial. In reality, I'm somewhere in the middle ground when it comes to the concept of open source – neither strongly for nor strongly against it. I can, and do, see both sides of the coin.
As I see it, open source has both good and bad points. On the negative side, it has been partially responsible for ripping the financial underpinnings out from under the software industry, and that is definitely bad. It seems clear that it is now almost impossible to make money writing software – not completely impossible, perhaps, but almost. The number of commercially successful software packages in this decade (the 2000s), compared to previous decades, is clear evidence of that. End users now expect most software (and web services) to be free. Often they won't accept or even consider software which costs money, even if it is markedly superior to the free option.
Consequently, most software "successes" today cannot charge directly for their product or service. Instead, they are forced to try to find indirect income streams (such as from advertising or technical support), and thus are usually not financially viable, being sustained only by funding from venture capital or a large, generous sponsor or parent company. YouTube, Flickr, MySpace, Facebook, Twitter, all lose money, some estimated to be hundreds of millions of dollars per year. Worse, there is no clear business model which will ever change that, unless you believe advertising is destined to be the ultimate savior of all such things, which I do not.
Open-source software is not solely to blame for this situation, of course – the nature of the World Wide Web itself shoulders a great deal of the responsibility, as does the venture-capital nature of Silicon Valley – but the open-source movement must bear its fair share of the responsibility for the "it must be free" mentality that now pervades the user community and undermines the financial viability of the software industry.
This "it must be free" mentality means that popular success in terms of adoption, and financial success in terms of profit, no longer go hand in hand. Even the web browser itself, clearly an incredibly successful and world-changing piece of software, has never been profitable as a product.
End users now expect most software (and web services) to be free.
The wider follow-on effects of such financial unviability are equally clear. The size of the software industry has shrunk considerably in recent years, with en-masse consolidation being the name of the game. Increasingly, there are fewer and fewer software companies, clustered around the few remaining categories of software which are still profitable – operating systems, image/video/audio editing, databases, engineering/CAD/3D-animation and games; with operating systems and databases beginning to appear under threat.
The era of the small, successful software company is largely over, sadly, and along with it the opportunity to "change the world" that so many young programmers seek. In lock step with this, the number of students undertaking computer-science courses at college/university has plummeted and remains at an all-time low (in percentage terms). And yet, ironically, all of this has occurred despite computing being more important to daily life now than ever before. The long-term future of this trend is less clear, since it seems unsustainable on the face of it, but it is fairly apparent that, at least for now, computer programming is no longer seen as the attractive career path it was once considered to be.
Despite such negatives, I am not completely against open-source software. Indeed, I think open source has three vitally important roles to play – in education, in infrastructure software, and for software representing ideas that are now mature and well-understood, where the remaining improvements are likely to be incremental – we do need to build on each other's work! Each of these will be discussed in depth later in this article.
I also believe that over the very long term things will swing back, or a more sustainable hybrid model will emerge. Financial incentive is a crucial ingredient for sustainable long-term success, where "long-term" means decades or centuries – the failure of socialism/communism taught that lesson quite clearly. Therefore, I believe there will and must be either a resurgence of commercial software development at some point in the future, or the evolution of some kind of financially viable model which would make open-source software development sustainable.
Freeware & Open Source
'Free software' is a matter of liberty, not price.
To understand the concept, you should think of
'free' as in 'free speech', not as in 'free beer'.
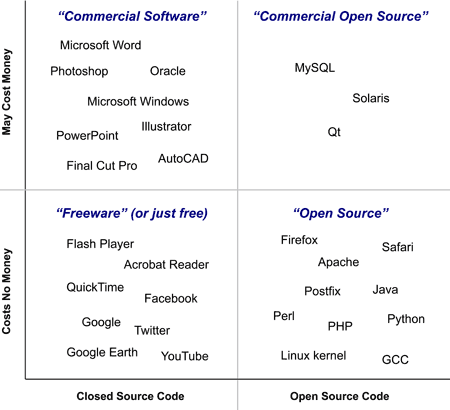
Before we go any further, it is critically important to note that there is a big difference between software which costs no money and software which is open source. The term "freeware" is sometimes confusingly used to mean both cases, as if they were one and the same. That is completely incorrect.
The terms are actually defined, normally, as follows...
- Freeware
- Freeware simply means "costs no money". That's all, nothing more. The original freeware programs were not open source at all – they were simply no-cost binary executables. Today, most open-source projects are freeware, but there are also many freeware programs which are not open source. Flash Player, Acrobat Reader, QuickTime, iTunes, Skype and Google Earth are all freeware but not open source. This use of the word "free" is sometimes called free as in free beer.
- Open Source
- Open source means that in addition to the binary executable, the actual source code of the program is made available to the users, typically via download, and can be freely modified and redistributed (assuming you have programming skills). To officially qualify for the name "open source" (which is technically a trademark), the source code has to be freely available – at no cost and with no NDA-style restrictions. This means you are free to change it, free to fix bugs, free to make improvements, free to port it to other systems, free to extend it in whole new directions and so on. This use of the word "free" is sometimes called free as in free speech.
- Free Software
- Free software is an older term the use of which is now discouraged. It was originally intended to mean what is now called "open source", but the double meaning of the word "free" meant that it was usually incorrectly interpreted to mean "freeware", that is, costs no money. Although there are still a handful of people such as the Free Software Foundation (FSF) who advocate its use, the general consensus was that it needed to be replaced with a term that was more naturally understandable to the general public, which is why the new term "open source" was invented to replace it in the late 1990s. It is truly unfortunate that the term "free software" was ever used, as it has caused enormous confusion by conflating the issue of source-code access with the unrelated issue of the software's price.
- Public Domain
- Public domain means an item is public information and has absolutely no restrictions whatsoever. It's essentially the opposite of copyright – when something expires from being under copyright, it is said to go into the public domain. The plays of William Shakespeare are in the public domain, for example. Any source code in the public domain is, by definition, open source, but not all open source is public domain (in fact, almost none is).
Open source is not about "free as in free beer", but rather "free as in free speech". That's the key point. It's about the kind of freedom found in the pure sciences like physics and mathematics, which is what allows new generations of scientists in those fields to build on the prior work of others. Computer scientists want, and I think need, such freedom too, it just hasn't been a major problem until relatively recently because computer science is such a young field.
Open source is not about "free as in free beer",
but rather "free as in free speech".
The misconception between freeware and open source, further complicated by the older term "free software", comes about because people think it's all about money, or lack thereof, whereas it's actually not about money, and all about access to the source code. In particular, business people tend to live lives so focused on money that they've basically forgotten there is any other meaning for the word "free" other than "free beer". Programmers, on the other hand, use the word "free" every day to mean things completely unrelated to money – allocating and then freeing (releasing, making available) memory, disk space and other resources; being free (allowed, having permission) to read and write certain files, connect to certain systems and so on.
I personally believe that's why most non-programmers don't "get it". They're locked in on the money aspect – free as in free beer – and they don't really understand the enormous importance of source-code access as a necessary part of being able to build on the work of others, rather than having to constantly reinvent the wheel. They don't realize just how much of a big deal that really is.
Open-Source Licenses
I remember the days of public-domain software. At least
back then no one spent all their time arguing about licenses.
Instead, people used their time writing or using software.
Most people think all open source code is in the public domain, but actually that's completely incorrect. Any source code in the public domain is certainly open source, but almost none of the open source code out there in the world is public-domain. Most open-source projects actually have licenses, which govern the code's use and protect the authorship so that somebody else can't claim to have written the code (I've had that happen to me a couple of times, and it's really annoying, to say the least).
One popular open-source license, the GNU General Public License (GPL), also forces all derivative works to remain open source, forever. The alternative BSD license, which originally comes from the BSD UNIX distributions, does not have this restriction, so it allows derived works to be either open source or regular commercial closed-source software. The Mozilla Public License (MPL) sits between these two extremes, allowing linking with commercial closed-source code but requiring any changes to the open source code to be made available as open source.
Here's a brief summary of each license (for full legal interpretation, see your legal advisor)...
- GNU General Public License (GPL)
- The GPL is probably the most common open-source license, but not the most "open". The GPL takes the unusual legal approach that any work derived from a piece of GPL'd source code must also be licensed under the GPL. In other words, if I make my source code available under the GPL, and you take it and change it, then you must make your modifications available under the GPL too. In requiring this, the GPL legally enforces a kind of give-and-take between programmers. Most open-source programmers see this as fair, because any programmers who use/modify/extend the source code are forced to give back "in kind". The GPL makes it impossible to take GPL'd open source code and turn it into closed-source commercial software. In this way, the GPL has a kind of viral nature – when any other source code is mixed with GPL'd code, the result is always GPL'd code. For this reason, the GPL is sometimes called a "copyleft" license. The Linux kernel and all of the GNU software uses the GPL (Emacs, GCC, GNOME etc). A slightly modified version of the GPL – the Lesser GPL (LGPL) – is used for GPL-style libraries, where modifications to the library code itself must be released as LGPL'd open source, but it's okay to simply use the library in a closed-source commercial application. So merely linking with GCC's C/C++ standard library, for example, doesn't mean commercial software products have to make their source code open to the public.
- BSD License
- The BSD license, which comes from the BSD UNIX distributions, is an alternative style of open-source license that's quite different from the GPL. It doesn't have the viral nature of the GPL, and is much more friendly towards commercial reuse of the source code. By placing your source code under the BSD license, you are saying it's perfectly acceptable for someone else to take your code and make a closed-source commercial product derived from it. They have to give you credit somewhere, but that's all. Many commercial products today are based on BSD-licensed open-source origins, particularly in the UNIX world. For example, Darwin, the UNIX core of Mac OS X, is based on FreeBSD UNIX, which is licensed under the BSD license. Similarly, the X11 Window System used by many UNIX operating systems has a BSD-style license (the MIT/X11 license), and many vendors have implemented commercial versions of X11 with higher performance, extra features, support for their proprietary graphics hardware and so on, keeping their modifications and additions closed. This couldn't be done with the GPL – under the GPL the results could not remain closed source and would have to be made available as GPL'd open source. The Apache license is a slight variation of a BSD-style license which adds a patent-sharing clause in an attempt to protect contributing programmers from patent litigation, but is essentially the same as the BSD license in spirit.
- Mozilla Public License (MPL)
- The MPL lies in-between these two extremes. It represents what many consider to be a reasonable compromise, largely because its license, unlike the others, was the result of public discussion and revision by the programming community at large, both open-source and commercial. Netscape was the first major piece of commercial software to be released as open source (resulting in Firefox today), and the MPL was actually "beta tested" before release to make sure all parties were satisfied. The MPL is a bit like the GPL in that it still has the "copyleft" style, but it specifically allows open source code to be combined with closed-source commercial code to produce a commercial product, as long as any changes to the open-source parts are made available as open source. The closed-source parts can stay closed-source, as long as the interface between open and closed code is documented. The idea here is that bug fixes and small, incremental additions/changes to the core code should stay open source, while any major commercially-viable new feature could be written as a closed-source module (with a documented API). For any commercial variant to be successful it would need to add a lot of value above and beyond the base open-source version, which helps to protect against unethical commercial exploitation, while still allowing commercial variants if there's real value added. Under the MPL, code contributions also explicitly give up all patent claims for the ideas expressed in the contributed code, which protects the project from patent litigation.
The take-home point here is that when a programmer writes a piece of code, he has a great deal of choice about how he can make it available to the world...
- He can keep it entirely to himself for his own personal use, for example a script to do some piece of automation like a backup.
- He can keep it to himself and use it internally just within his company, such as an in-house business application to give the company a competitive advantage by reducing costs.
- He can keep it to himself but expose an interface to it as a service over the web, like the Google search engine, eBay, or Flickr.
- He can sell compiled binary copies to the public but keep the source code to himself, such as Microsoft Word or Photoshop.
- He can give binary copies away for free but keep the source code to himself, such as iTunes or Acrobat Reader.
- He can share the source code with the world, more or less without restrictions, by using the BSD/MIT/Apache licenses, such as FreeBSD UNIX or the Apache web server.
- He can share the source code with the world, but require anyone who uses it to also share their source code with the world, by licensing it under the GPL, such as GCC or the Linux kernel.
- He can share the source code with the world, require anyone who changes it to share their changes, but otherwise allow anyone to use it more or less without restriction, by licensing it under the MPL (and/or LGPL), such as Firefox.
Commercial Open Source
So a lot of the really rabid free software people seem to often
think that it's all about the developers, and that commercial
interests are evil. I think that's just stupid. It's not just about
the individual developers; it's about all the different kinds
of interests all being able to work on things together.
Another aspect of the idea of open source that is critically important to understand, and often misunderstood, is that being open source doesn't necessarily mean you can't sell the compiled binary executable for money. That's right – contrary to popular belief, open source is not about being anti-money.
Most people just don't get this, but in fact, attempting to sell the compiled binaries of open-source software is perfectly acceptable and legal – although whether it is ethical or not depends, at least in my view, on whether you were really the one who wrote most of the software or not (more on this later).
Of course, most open-source projects are also freeware. Most, but not all. The Qt GUI library at the heart of the KDE Linux desktop, for example, is dual-licensed such that it's open source but must still be purchased when used to develop commercial software. If you've used Google Earth, you have used just such a commercial application – its GUI is built using Qt, which Google presumably paid for. The MySQL database has a similar dual-licensing situation, and many commercial web sites buy commercial licenses in order to use the open source MySQL database on their servers. Most recently, just last month (May 2008), Sun Microsystems released its entire Solaris UNIX operating system as open source, whilst continuing to sell hardware, patch subscriptions and support contracts around it.
Contrary to popular belief, open source
is not about being anti-money.
The area inhabited by the likes of Qt, MySQL and Solaris is sometimes called "commercial open source". I believe it is one of the most interesting and important areas, because it allows commercial companies to open their source code to the world without necessarily having to give up all of their income.
Of course, since the source code is available and could be compiled by the users without paying, it is more difficult to police the sales of such a product. However, as commercial music sales on the Internet have shown, as long as the pricing is reasonable, many people are quite happy to do the right thing – and those who aren't would probably circumvent any commercial copy protection too, so you're really not missing out on sales from them anyway.
Nonetheless, it clearly isn't going to be easy to make money developing open-source software. John Ousterhout, the creator of the Tcl/Tk scripting language, points out the difficulty: "It's hard to make money off open-source software, which means there aren't very many successful companies based around open-source software. I started a company around Tcl in 1998, but it became clear within a year or two that we couldn't create a very large business. In order to create a business around an open-source package, there needs to be a truly huge user community (in the millions), such as Linux or MySQL. Tcl had a community of hundreds of thousands, but that wasn't enough for a business. If it were easier to make money from open-source software, then it will be possible for more people to work on it."
Hundreds of thousands of users, and yet still not enough for a viable business? That's not a good sign.
And yet, I believe some form of commercial open source may well be the way to make open-source software development financially viable, and therefore sustainable. Many approaches will need to be tried, and time is needed to evolve the business model. Many people will need to be willing to take huge risks, and many will probably fail, but ultimately I believe the idea of commercial open source ought to be viable. It should be interesting to watch, and perhaps participate, during the next few years and decades, as the pioneering commercial open-source products and companies either evolve or die out.
On the topic of commercial open source, it is also interesting to note that a surprisingly large amount of the most important open-source software is commercially backed – such as Safari/WebKit and Java – even if not literally commercial open source in the sense of trying to make money directly from it. Add to that list Firefox and Postfix, both formerly commercially backed, and it seems clear that commercial and commercially backed open source is far from a rarity. In fact, commercial involvement may well be critical to the open-source movement's long-term success.
At this point, however, it would be remiss of me not to mention that there are a group of people within the open-source movement who are strongly opposed to the idea of commercial open source. They essentially take the view that all open-source software should also be freeware. In my experience this is, by and large, a minority view among open-source programmers, but unfortunately tends to be somewhat more common among open-source end users. I believe a lot of this attitude comes from misunderstanding the goal of open source, as well as a large amount of pure, unadulterated self interest – the truth is, a lot of these users are just plain cheap, to put it bluntly (but accurately). The key point, though, is that this is a minority view, and most open-source developers are not anti-commercial.
Whether commercial open source or freeware open source, opening up your source code also opens you up to competition. In effect, it gives your would-be competitors a "leg up", letting them catch up to you quickly by using your source code rather than reinventing the wheel from scratch themselves. Just how much of a leg-up you are giving them depends very much on the nature of the software. For some things you might be giving them a tremendous help, without which you would have had little or no competition for quite some time. For other types of software both the ideas and the implementation are fairly obvious, and your competitors are bound to write a copy anyway, so you're really only accelerating the inevitable leveling of the playing field while possibly gaining some public-image and branding credibility as the original developers of the technology – an image your competitors then have to compete against if they choose to adopt your open source code base.
For this reason, I think the right approach for the software industry in the long term is to have closed-source commercial software during the early days of a really new idea, to protect and reward the true inventors, then to move to a commercial open source model once that invention becomes mature and well-understood. That way, new people are free to "take up the banner" and build the next generation of technology from the work, without having to also rebuild the original work itself. When and if that finally happens, it should actually be seen as a good thing, even by the original developers. If other programmers can take your source code and, by building on your work, generate a greatly enhanced version of your product, such that your own offering is no longer competitive, then that's progress. That's not a bad thing, it's a good thing. In fact, that's the whole point of going open source – it allows others to build on your work. Of course, one would hope that the "new custodians" of the technology which was once yours are generous and acknowledge the people who came before them, just as in the pure sciences.
Innovation & Copying
Improvement makes strait roads, but the crooked
roads without improvement are roads of genius.
Richard Stallman's original GNU Manifesto essentially claimed that all software should be developed and distributed as open source, because that's a step towards a "post-scarcity world" in which "drains" like competition are eliminated and progress flourishes, because progress is about people making improvements to other people's work, and with software that requires access to the source code.
At first glance, such a claim does sound reasonable – at least the progress part – but is it? Does source-code access really accelerate progress? Certainly for small, incremental improvements it obviously does. It's easier to add an enhancement to an existing piece of software than to write the whole program from scratch, especially if the program is large. No reasonable person would argue against that. But computing has historically been all about big leaps, not small, incremental improvements. What about open source in the realm of major innovations? What about the big picture?
Open-source software has been around for a long time now – it started way back in the 1980s with BSD UNIX, the X Window System and the GNU project. In that time there have been many successful open-source projects, certainly, and yet all of the major advances in software, the ones that really matter and shape what we do with computers, have come from either commercial software or closed-source government research projects – TCP/IP (DARPA), the UNIX operating system and C programming language (AT&T Bell Labs), the graphical user interface (Xerox PARC and Apple), object-oriented programming (Xerox PARC and AT&T Bell Labs), 3D graphics (Evans & Sutherland, Silicon Graphics), the World Wide Web (CERN), the web browser (NCSA and Netscape Corp), solving the search problem (Stanford University and Google), social networking (MySpace, Facebook, Twitter), multi-touch interfaces (AT&T Bell Labs, Apple, Microsoft); or through small groups of experts assembled for standardization efforts (JPEG, MPEG etc).
Open-source projects are nowhere to be seen on the list of the major breakthroughs in software.
Even looking to lesser breakthroughs, in recent times it has clearly been Sun doing most of the running in low-level OS technologies (the ZFS filesystem, fine-grained process rights, virtualized containers/zones, dynamic tracing); Apple doing most of the running in user interfaces and 2D graphics (compositing window system, advanced 2D graphics, GPU-accelerated image manipulation, multi-touch); the commercial games industry doing all the running in 3D graphics (programmable shaders, high-dynamic-range rendering); traditional commercial tools such as Photoshop, Final Cut Pro, Maya and AutoCAD continuing to lead the way in content creation; and in web browsers recent innovations like tabs, thumbnail previews and session saving/restoring have come from the commercial niche browsers Opera and OmniWeb. It is really only in the area of programming languages that open source has made any significant innovations (Perl, PHP, Python and Ruby), and even there we must not ignore the commercially-originated "big guns" of recent languages: Java and JavaScript.
Based on the evidence, so far there just haven't been any real breakthroughs to come from the open-source movement. None. I'm sure one will, eventually, but it certainly hasn't happened yet. I don't say this to be dramatic or antagonistic, it is a legitimate question. If Stallman and Raymond are right, and open source truly is a better way, then most of the breakthroughs ought to be coming from that type of development. Even if they are only half right, and open source is only an equally good but different way, then at least some of the breakthroughs should have come from open source. That simply hasn't been the case.
Which brings us to a crucial point – nearly all open-source software is just a copy of some piece of older commercial software. Many open-source advocates don't want to admit this, but it's true. Today we live in a world of copying, sadly, and the open-source movement is just as guilty of it as Microsoft. Richard Stallman freely admits this: "Normally, if a proprietary program is widely used, we try to recruit people to develop free replacements for it". Even the original open-source projects were copies – BSD UNIX was a rewrite of AT&T UNIX, and the X Window System a copy of the GUI work pioneered at Xerox/Apple. Both had some new, innovative features, certainly, but both were clearly copies of other people's ideas for the most part.
Nearly all open-source software is just a copy of some piece of older commercial software. Many open-source advocates don't want to admit this, but it's true.
Many people, especially the media, tend to treat Linux and open source in general as some new breakthrough technology. Linux isn't a new, revolutionary technology. Linux is a copy of the UNIX kernel, and a straightforward copy at that, with a conventional monolithic design and very little that's new or different about it. The Linux kernel has benefited from being a fresh rewrite of the UNIX kernel 20 years later, but it's still very definitely a rewrite of the same old ideas. GCC isn't revolutionary either, it's just another C/C++ compiler, with a very conventional design for an 80s-era compiler. GNOME and KDE are clearly just trailing copies of the Mac and Windows GUIs, with a handful of minor visual differences thrown in to make them unique. As a general rule, Linux has always been playing catch up with its commercial UNIX brethren, and while it has definitely closed the gap, features like Sun's ZFS filesystem and Dtrace, or Apple's GUI, show that Linux is still playing catch up today.
But it's okay that Linux isn't revolutionary from a technical point of view, because Linux is still revolutionary. The thing that's revolutionary isn't the technology in Linux, it's the distributed, collaborative style of development.
The fact that massively distributed open-source development works at all, and doesn't simply fall completely apart, has shown us several things. Most obviously, it shows that you really can have a situation where thousands of programmers work together without ever meeting in person, thanks to the wonders of email and the World Wide Web for communication, the advent of modern version-control systems for coordination, and clean, strongly modular software design (as exemplified by UNIX). None of that is specifically related to open source though – it could be applied for commercial software development too, and we're starting to see that today (not in the thousands yet, but certainly in the hundreds in some cases).
It also shows that many people really will voluntarily contribute their little bit to the whole, be it a bug fix, porting to a new system or device, some minor feature they personally want, or a more substantial contribution. I can remember a time when there were serious doubts about this, given that there is no financial reward to be had, but no longer – it is now a well-established fact.
Open source similarly shows that you can get by with a vastly smaller management structure than traditionally believed, because a motivation-based, self-selection system seems to work just as well as any traditional management hierarchy at assigning and monitoring tasks, some would say better. This raises real questions over the value of conventional software-development managers. Once again, this is not specific to open source, and a handful of commercial software companies are already beginning to adopt the same idea and allow programmers to self-organize and self-select at least part of their work (eg: Google's "20% time").
Perhaps most surprisingly, open source shows that many programmers are motivated far more by the opportunity to make a difference than by money, even to the point of willingly giving up monetary compensation in order to work on something they consider worthwhile. It has long been observed that in this way programmers tend to be more like artists, musicians or authors, despite the technical nature of the work. This may explain the dissatisfaction levels of programmers in many software companies despite their high pay.
Finally, open source shows that the installed base of existing, experienced end users themselves provide a support/help system of surprisingly good quality and reliability – at least as good as most traditional official support channels, and often better than the classic call-center support offered by many companies. This is something commercial software companies have been watching closely and learning from, and user forums and wikis are now becoming common on the web sites of many commercial software products.
The thing that's revolutionary isn't the technology in Linux,
it's the distributed, collaborative style of development.
When you think about it, the distributed, collaborative style of development has achieved some impressive, even amazing things. But let's not get carried away. In reality, the type of improvements that access to the source code itself allows are mainly bug fixes ("Given enough eyeballs, all bugs are shallow." – Linus's Law), porting to new systems/devices, and the addition of small, specific, and usually relatively minor features. Anything more than that, especially a major design change, is still basically restricted to the handful of inner-circle "core" programmers of whatever the project is. That's really no different from any commercial situation.
This shouldn't be unexpected – the same applies in most other fields of human endeavor. It's a well-known fact that in order to achieve a simple, clean design for any complex system, the design should be done by as few people as possible. That's why UNIX has a clean design, where Microsoft Windows does not. It's what makes TCP/IP work, where other, more elaborate networking models were unwieldy. It's a basic principle behind nearly every successful technology from the C programming language to the World Wide Web. Too many people being involved in the initial design phase ends up producing an overly large, overly complicated design that ultimately reduces the chances of success. Everybody knows that. It's the "design by committee" problem. Even Eric Raymond's original CatB paper admitted that initial design or major redesign really can't be done in an open-source fashion: "It's fairly clear that one cannot code from the ground up in bazaar style".
So, in practice, while highly distributed open-source development does seem to work well for allowing small, incremental changes/improvements, it doesn't help with the initial breakthrough inspiration, it tends to complicate the design, and it actually hinders the major structural design changes that real breakthroughs usually require. Doing a major restructuring of a code base is often much harder in an open-source situation.
Fragmentation & Forking
The very essence of leadership is that you have to have a vision.
It's got to be a vision you articulate clearly and forcefully
on every occasion. You can't blow an uncertain trumpet.
Highly distributed open-source development also has another major problem – focus and direction. It's a fact of basic human nature that different people will frequently have different ideas about how best to solve a given problem. That's okay, and even healthy up to a point. In the largely uncontrolled and undirected open-source world, however, it's a recipe for disaster.
Without any centralized control, multiple different open-source projects often spring up trying to fill the same basic need within the overall software ecosystem. This wastes a great deal of scarce and valuable programmer time and effort. The competing projects rarely combine, and because they're open source, they rarely die off – they just keep on wasting effort and draining programmer resources for years.
Worse still, even the individual projects themselves sometimes split, or "fork", due to differing opinions among the developers. Merely suggesting a major design change may well offend or alienate the project's original programmers, causing forking, as happened in the famous cases of GCC/EGCS and Emacs/Epoch/Lucid.
Fragmentation and forking is the number one problem in open source. What the open-source movement gains in terms of head count, diversity, motivation and enthusiasm, it loses in terms of control and direction. This leads to two major problems. First, you have a great deal of very similar work being done in duplicate, triplicate or worse. Second, from the outside viewpoint it looks like total chaos (and on the inside some would say it actually is). To the "newbie" user, having a dozen different Linux distributions to chose from makes them feel nauseated, not fascinated.
The fragmentation problem happens largely because there really is no central controlling authority to steer the ship, no "head honcho" in the way that, say, Steve Jobs has ultimate decision-making power at Apple, or Bill Gates had at Microsoft. So whenever people's opinions differ over some issue in the open-source community, it ends up splitting the community. Sadly, this seems to happen over nearly every major issue, and even some minor ones.
Fragmentation and forking is the number one problem in open source. What the open-source movement gains in terms of head count, diversity, motivation and enthusiasm, it loses in terms of control and direction.
Thus, today in the open-source world there is active development of 3 different kernels and userlands (Linux vs BSD vs Solaris), 4 different filesystems (ext vs ZFS vs Btrfs vs NILFS), 4 different boot-script systems (initng vs upstart vs SMF vs launchd), 4 different package systems (apt vs rpm vs portage/ports vs ips), 3 different version-control systems (Subversion vs Git vs Mercurial), 2 different X-Window servers (XFree86 vs Xorg), 3 different GUI toolkits (GTK+ vs Qt vs wxWindows), innumerable window managers (Metacity vs Enlightenment vs Sawfish vs Fluxbox vs KWin etc), 2 different desktop environments (GNOME vs KDE), 2 different web browsers (Firefox/Gecko vs Safari/WebKit), 3 different email clients (Thunderbird vs Evolution vs KMail), 2 different office productivity suites (OpenOffice vs KOffice), 3 different video players (MPlayer vs VLC vs Xine), and so on and so on, ad infinitum. It's miraculous that there is still just one main compiler, but even GCC was forked in the past (remember PGCC and EGCS) and a new open-source compiler project has recently been started (Clang/LLVM).
The situation is a complete shambles – so much for the GNU Manifesto's original idea of eliminating the "drain" of competition! And that's not even counting the higher level of whole OS distributions, where there are 3 distinct versions of BSD (FreeBSD, NetBSD, OpenBSD) and at least half a dozen major Linux distros (Ubuntu, Debian, Fedora, RHEL, SuSE, Mandrake, Gentoo), each slightly incompatible with the others. Arghhh!!!
There is an awful lot of "reinventing the wheel" going on here, and most of the work will ultimately be thrown away, wasting thousands of man-years of programmer effort. Granted, commercial software development also has a large waste factor – it's common knowledge that at least half of all software products are rejected by the marketplace – and granted there has been some spectacularly unproductive forking in the commercial software world too, such as the many variants of commercial UNIX in the 1980s and '90s (the "UNIX wars"), but open source is supposed to be about everyone working together for the common good, not everyone working against one another. I believe competition is a great thing for progress, but there's already plenty of competition between Microsoft, Apple, Sun and the Linux and FreeBSD movements. Nobody is being lazy due to lack of competitive pressure.
There may be an argument that the competition between the ZFS and Btrfs filesystems is good for progress, and similarly between Firefox and Safari, because these projects are at the cutting edge of progress in their respective fields. It is quite clear, however, that the divisions and waste of effort between less cutting-edge projects like, say, GNOME vs KDE, or Mplayer vs VLC vs Xine, are only hurting the open-source movement. There's a famous Aesop saying – "United we stand, divided we fall" – and the open-source movement is chock full of division.
In large-scale software development, you really do need someone to take a "big-picture" view, make a decision, and get everybody to stick to it. Within companies it is possible to achieve this, at least for the most part, perhaps occasionally losing a few good programmers when they strongly disagree with the company's decision. In the open-source world it just isn't possible to enforce this kind of thing at all.
Even if the Linux community appointed Linus Torvalds as the sole person of ultimate power to make the big policy decisions – a "benevolent dictator for life" in Linux speak – not just for the kernel but for the whole operating system, it probably still wouldn't work. Whatever he chose, you can bet the programmers of the other alternatives would disagree and become disgruntled, and people can get ugly pretty quickly when that happens. Disagreement is a fundamental part of human nature, and getting people to agree and cooperate, against their own self interest, requires exceptional charisma and people skills. There is a reason politics is the world's second-oldest profession.
Can you imagine the reaction to decisions like: "development of the BSD kernel and userland will be stopped, we're going with Linux from here on", or "KDE will be dropped, along with all Qt-based apps for which there's already a reasonable GNOME equivalent, with any remaining apps converted to GNOME ASAP", or "all Linux distros are to be cancelled except Ubuntu, which will from here on be simply called Linux".
These are exactly the types of big-picture, high-level strategic decisions that need to be made, and they just can't happen in the open-source world. Rather than dropping their cancelled project and switching over to work on the chosen project, the disgruntled programmers from the cancelled projects would almost certainly disagree with the decision, ignore the "command" and continue working on their own project – "who are you to tell me what to work on, I'm not your employee you know!" Just look at what happened when GNOME switched from Enlightenment to Metacity as its default window manager. Enlightenment didn't die off, nor did the programmers switch to working on Metacity. Instead, they started to build their own desktop environment (the "desktop shell"), effectively a future competitor for GNOME and KDE. Arghhh!
In practice, the fragmentation problem is effectively unsolvable, because any "benevolent dictator for life" of Linux is essentially a paper tiger, with no real power to make his decisions stick. Even the original CatB paper admitted this: "The principle of command is effectively impossible to apply among volunteers".
Perhaps that's why most successful open-source projects are copies of commercial products. As Microsoft's Jim Allchin observed: "Having a taillight to follow is a proxy for having strong central leadership". There does seem to be a lot of truth to this statement (although Microsoft also does a lot of taillight chasing, so they're hardly in a position to throw stones).
Teaching, Research & Exploration
It is paradoxical that many educators and parents still
differentiate between a time for learning and a time for
play without seeing the vital connections between them.
Even though I don't believe highly distributed open-source development is necessarily conducive to major breakthroughs, and it does seem to cause a lot of wasted duplication of effort through forking and fragmentation, I think there is definitely still a place for open-source software.
One area where open source is a good fit is clearly teaching. Open access to source code has huge benefits for teaching, because it gives young programmers a chance to work on large, real projects before they join the industry. This is a good thing, and desperately needed. Many computer-science graduates today have never worked on anything larger than a couple of thousand lines of code, so they don't really "get" the things that matter when you write code for a large piece of software – basic but crucial things like being really deliberate about keeping functions small and relentlessly looking for commonality to extract out, or reading and understanding a large code base written mostly by strangers.
Similarly, many computer-science graduates today only have a superficial, theoretical understanding of system internals. This is frustrating, but completely understandable. How can we expect our young programmers to learn about things like OS kernels, networking stacks or graphics libraries if they never get to see inside a real one? That would be like teaching young doctors and nurses by showing them nothing more than descriptions and diagrams, never dealing with real patients or seeing inside a real body. Viewed in this light, open-source software can provide students with an opportunity similar to internship or residency in the medical field, a sort of bridge between classroom teaching and real-world practice.
How can we expect our young programmers to learn about things like OS kernels, networking stacks or graphics libraries if they never get to see inside a real one?
Equally importantly, open source allows both young and not-so-young programmers to do serious work in areas of the system which would otherwise be off limits, such as the kernel, standard libraries, networking stack, graphics system and GUI toolkit. Without open source, a programmer can really only work at the application level, above the system, or on device drivers or other highly modular, plug-in-oriented parts of the system (eg: filesystems, compilers). They are basically excluded from the core kernel, standard libraries, networking stack and graphics/GUI system unless they go and get a job at Microsoft, Apple or Sun. That's extremely limiting, especially for international programmers who don't want to move to America (and that's most of the world, remember). It is important if you're a hobbyist wanting to work in one of those fields, and it is a critical issue if you happen to be an academic researcher in one of those fields.
So I definitely think open source has a place within the teaching arena, and within the related areas of hobbyist exploration and academic research (which are arguably the same thing, IMHO). Perhaps this shouldn't be a big surprise, given the open-source movement has its origins in the world of academia – BSD UNIX gets its heritage from UC Berkeley, both the GNU project and the X Window System were originally strongly connected to MIT, and the development of Linux was supported by the University of Helsinki for many years. Even today, it is clear that quite a lot of open-source development activity comes from university environments, either as explicit teaching/research or as a reaction to not wanting computing to become completely corporatized ("Borged").
In fact, it has even been suggested that open-source software development is really just a new form of academic research, or at least shares a lot in common with it. In some ways I tend to agree with that characterization – though not a perfect fit, in my experience it's much closer to the reality than the other common analogies I've heard, like utopian idealism or some kind of technological socialism/communism.
Open-source software has a natural place in its "homeland" of academia, where things like vendor neutrality and source-code access matter most. Of course, it has moved well beyond just an academically interesting system nowadays, and is being used in some decidedly non-academic situations, such as most commercial network servers on the Internet. But ultimately I think it's correct to see quite a lot of the open-source movement as an academically-based phenomenon (where the word "academic" is not confined to mean just official academic institutions by any means).
Internet Infrastructure
Open source couldn't really exist without the Internet.
And vice versa.
No matter how you look at it, open-source software certainly plays a major role in the Internet. In fact, it's not an understatement to say that the infrastructure of the Internet practically runs on open-source software.
Every time you visit a web site you're almost certainly using a whole slew of different open-source software. The DNS server which looks up the site's IP address is probably open source (BIND). The web proxy cache that your request goes through is probably open source (Squid). The web server itself is probably open source (Apache). Any server-side scripting is probably written in an open-source language (PHP, Perl, Python, Java, Ruby), and if it connects to a database then that too is probably open source (MySQL or Postgres). All of these are probably running on an open-source OS (Linux, FreeBSD or Solaris). Just about the only parts of the whole process that probably aren't open source are your machine's OS (probably Windows) and your web browser (probably Internet Explorer) – and even here there's a significant chance you're using an open-source browser such as Firefox or Safari.
On the other hand, the content of the web site you visited was probably created almost exclusively with regular, closed-source commercial software. The textual content was probably originally written using Microsoft Word. Any charts or tables were probably generated using Excel. The HTML and CSS were probably created using Dreamweaver or GoLive. The images were probably prepared with Photoshop. Any animations were probably done using Flash, and any videos were probably edited using Final Cut Pro or Premiere. Any PDF files were probably generated using Acrobat. Just about the only part of the content-creation process which might have used open-source software would be "active" web-page sections, which might use an open-source JavaScript library, or might not.
I believe this strong distinction actually makes perfect sense. It matches the two different types of software nicely. Think about it for a moment. For infrastructure, what really matters is interoperability. All of the servers out there need to talk the same "language", so we have standards. Since all of these infrastructure daemons (servers) adhere to a set of common global standards for things like HTTP, DNS and SMTP, it is difficult to see how one daemon for a given protocol can really be dramatically better than any other. There's not much room for product differentiation, because all servers for a given protocol are really pretty much the same – they perform a relatively simple, well-defined task that is heavily standardized. The market even actively fights against differentiation for infrastructure software, because the users who make up the market know that in the long run such differentiation ultimately leads to incompatibilities, and that's the last thing users want in something as important as infrastructure, on which everything else depends.
Any improvements in infrastructure software are usually the result of small, incremental changes – performance improvements, reliability improvements, configuration/administration improvements and so on. Functionality improvements need to come via a standardization process. Such a situation is ideally suited to open-source development – open source is particularly suited to allowing small, incremental improvements, and the mere presence of a publicly-available open-source implementation for a given protocol tends to act as a kind of stabilizing force, preventing commercial vendors from going off in their own direction too much or interpreting the standard in a different way.
In addition, in infrastructure the issue of reliability is critical, so open-source software is preferred simply because of its open nature – if something goes wrong it really helps if you can fix it yourself, rather than being dependent on some software vendor to fix it for you. The same goes for security, perhaps even more so. It's almost impossible to truly trust that something is secure without having seen the code yourself, and security isn't something you want to be making hopeful assumptions about, especially at the infrastructure level where it affects everybody. The bottom line is that you don't generally want pieces of critical infrastructure to be depending on any one company, no matter how big or responsive or careful they appear to be.
Thus, for all these reasons and more, we tend to end up with highly successful open-source projects for infrastructure software, benefiting from the "many eyeballs" of open-source programmers to increase reliability and security, acting as a stabilizing force to prevent fractures in the standards, and avoiding dependence on any one company. You can make a very good case that all infrastructure software should be open source.
You can make a very good case that all infrastructure software should be open source.
The second type of software on the other hand, things like content creation, is very different. First, just by looking at the commercial offerings it is immediately obvious that there's much greater feature differentiation between products. This is largely because the products in any given category usually don't have to work to any common global standard. Instead, each individual product is free to go off in any direction it chooses, and doesn't have to worry about getting standards bodies to adopt its ideas and suggestions. This situation is much more suited to major innovations, something open-source development has not been particularly good at so far (see earlier discussion).
In addition, reliability is much less important for content-creation software – when a program like Microsoft Word, Photoshop or Dreamweaver crashes, it might be annoying to the end user, and might even lose an hour's work in the worst case, but it is not going to take down the whole company. So there's no great need to have source-code access so that you can go in and fix the code in an emergency. In most cases, source-code access wouldn't help anyway, since it's doubtful the end user would have the necessary programming skills to make use of it, unlike a system administrator running some infrastructure server, where he may well have programming skills himself, and if not he almost certainly knows someone who does.
Even the idea of being able to build on the work of others applies less strongly here, since access to the source code is somewhat less necessary at this higher application level. Programmers who wish to extend content creation applications can often be catered for quite well with some kind of "plug-in" architecture or scripting facility, which usually isn't true for, say, modifying how the compiler, networking stack or window system works. It's interesting to note that content-creation applications have historically been quite good at providing plug-in mechanisms to allow such extension by third parties, which is something the OS vendors could definitely learn from. Perhaps this is another reason why content-creation applications have been better able to withstand the "onslaught" of open-source software.
The bottom line is that for content-creation applications, the benefits of being open source are much smaller – reliability is less important, and a decent plug-in architecture can give you most of the extensibility benefits without having to make the source code public. Plus there is a lot more opportunity for real diversity and differentiation between competing products, since interoperability and global standards are less of an issue. Thus, we have highly successful closed-source commercial software in those segments, with open source playing little or no role.
Chasm/Tornado Theory – A Failure of Capitalism?
All in all, it was quite clear that whatever the merits of free market
economics, they were not at work in the software marketplace.
There is also another way to look at the open-source movement. In many ways, it can be considered a reaction to the failure of capitalism in the software industry, which is essentially ruled today by a handful of monopoly players, despite their offerings being overpriced and sometimes technically inferior products. Indeed, an anti-Microsoft stance is common to nearly all open-source programmers. Given such a dire situation, it's very tempting to think along desperate lines – if you can't beat them by having a better commercial product, perhaps you can beat them by having a better product which is also free (as in free beer).
Frustration with the current state of the software market is certainly understandable. No matter how you look at it, and no matter how much faith you have in free-market economics, the capitalist system has produced a software industry where almost any given segment is utterly dominated by a single product. Can you name any other industry where a single company has a 90% global market share? Is that a healthy market? Almost certainly not. Not only that, but many of the dominant products are, by any reasonable measure, only mediocre at best, and rely mainly on vendor lock-in (also known as backward compatibility) for their continued success.
How is this possible? The answer lies in the nature of software, specifically it being such a naturally layered system. Vendor lock-in is an inherently anti-competitive idea, designed to prevent true competition between vendors. And yet compatibility is essential in any layered system such as software.
What's ideally needed in a highly layered system is lots of competition within each layer, in order to drive improvement and progress through competitive pressure, while at the same time having all of the alternatives within a given layer be compatible with each other, so that the layers above can be built on a stable, reliable base.
A simple example of a good situation in this respect would be Ethernet hubs, switches and routers. In that market segment there are plenty of competitors, many of which add their own extensions and features, but all of the products are essentially 100% compatible – you can switch from one to another with minimal cost and effort, so there's really no lock-in to prevent competitive forces from working properly. Most of the hardware world works this way – hard drives, RAM, motherboards, graphics cards, even mice and keyboards.
In the software world that doesn't seem to happen. And it's not just operating systems that I'm talking about. Think about it – in almost every software category there's a single, overwhelmingly dominant product. Windows has 90% of the OS market, Microsoft Word 90% of the word-processing market, Photoshop 90% of the image-editing market, iTunes 90% of the music-player market, and so on.
In each case, the desperate, overriding need for compatibility from the public, combined with the extreme complexity of software layers (compared to hardware), causes overwhelming pressure for the world to unify on a single product. This is necessary in order to build the layers above, whether that's applications sitting on the OS, or document sharing based on Word files, or training courses based on Photoshop. The public actually deliberately kills off the other competitors by unifying on a single product – a de facto standard – thereby defeating the idea of competitive forces and the free-market model.
The only cases where this doesn't happen are markets where a true, agreed standard exists, to which all the products adhere. One such example is database software, where the SQL language is the agreed standard. Switching between, say, Oracle, DB2, Sybase, Postgres and MySQL is fairly easy, since they all speak the same SQL language (more or less). As a result, there's a healthy level of competition in the database market, and no one product utterly dominates the whole segment. Web browsers are another example, the common standard being HTML, CSS and JavaScript. Again, because of the standard, an end user can easily switch from one web browser to another, so there's no lock-in.
The most complex of the layers, of course, is the operating system, since it presents by far the most complex interface to the layers above it. Here the world did once have a hope for an open standard – UNIX. At one time, there were many vendors all building systems that were, more or less, compatible, because they were all UNIX variants. Yes, there were minor incompatibilities between the variants (a bit like the minor variations of how different web browsers support the corner cases of HTML & CSS today), but as a general rule, having UNIX as a common standard allowed healthy competition within the OS market, while still providing enough stability for applications to be easily written to run on any of the UNIX variants.
I believe much of the open-source movement today aspires to displace Microsoft and regain that UNIX-based situation, with its relatively level playing field and relatively little vendor lock-in. Indeed, this is sometimes called "Bug #1" in the open-source world ("Bug #1: Microsoft has a monopoly market share").
Just as there has been a failure of competition and/or capitalism at the software-market level, there has also been a similar failure of competition inside large software companies. Unfortunately, within large companies (of any kind) the good ideas and people rarely rise to the top, which perhaps explains part of why most breakthroughs in software have come from small start-ups, not large, established companies. Sadly, as is often the case in other fields, "it's not what you know but who you know" that really counts inside large companies. Good ideas are often lost because they get killed by the chain of command – the deep and highly political management structure.
In stark contrast, the world of open source is very much a meritocracy. Contributions are accepted or rejected based almost entirely on technical merit. Politics rarely comes into it (not never, but rarely). If you have a good idea, you can just do it. You don't have to get permission or approval from a higher authority, and it doesn't matter who you know or what influence they have.
Commercialization & Exploitation
What we obtain too cheap, we esteem too lightly;
it is dearness only that gives everything its value.
Finally, let's get down to brass tacks. I believe that expecting all software to be available for no money is not just unrealistic, but logically incorrect thinking. Richard Stallman's famous statement: "The prospect of charging money for software was a crime against humanity" is clearly an extreme viewpoint, as is "If your program is free software, it is basically ethical". We must remember Stallman is a person who chooses not to own a house, a car or even a cell phone, not for lack of money, but as a matter of principle. Whether you believe he is right or wrong, he is clearly an extremist.
By any reasonable measure, software has real value, otherwise why do you want it? Seriously, this is worth thinking about. If it had no value to you, you wouldn't want it. So it must have some value. Money is just an abstract form of value, nothing more. So naturally software is worth money, just like any other goods or services that have value.
Equally, software takes real time and intellectual effort to write. Therefore, it has real costs. Initially those costs are in the "pure" form of time and effort, but they must still be paid. In the commercial world, they are paid by the programmers, who in turn are paid back by the company, mainly in the form of money, but also in less tangible forms such as status, self-satisfaction and so on. The company, in turn, is paid money by the product's users, who themselves are (hopefully) ultimately paid back by either some capability, some functionality, some productivity, performance or reliability gain, some entertainment value, or a combination of the above.
Software has real value, otherwise why do you want it?
If it had no value to you, you wouldn't want it.
In the voluntary open-source world, at least in my experience, things really aren't all that different. The cycle is often just somewhat short-circuited. The initial costs of time and effort are paid by the programmers, who are then usually paid back by either some relatively direct capability, functionality or productivity gain useful to themselves because the programmer is also a user, or by money from some company "sponsoring" the open-source project (by Mozilla's own admission, the overwhelming majority of the code is contributed by people being paid one way or another to work on Firefox).
Just as in the commercial world, there are also less tangible but no less real paybacks in self-satisfaction, status and so on. In fact, these intangible forms of payback tend to be greatly accentuated in the open-source world, compared to commercial development, because in the commercial world the company wants to take credit for its products, at least in public. On the self-satisfaction front, it's immensely satisfying to give something away to mankind as a whole. So open-source programmers are still getting a payoff, just not always in financial terms.
A key question, then, is how should commercial software really be priced, given that most commercial programmers typically aren't solving problems for their own direct benefit, self-satisfaction or public credit?
That's a difficult question to answer, due to the nature of the goods. From an economic viewpoint, computer software is quite different from almost all other products. For most products, the cost of designing is very small compared to other per-unit production costs. A car is a good example. Less than 5% of the price tag of a modern car is for the time and effort to design it. Nearly all the cost is in the raw materials (metals, paints, leather), the manufacturing process (running the machines and paying the assembly-line workers), and distribution (shipping, paying the salesmen etc). The same applies, more or less, to almost all high-volume products.
Software, on the other hand, costs essentially nothing to distribute today, and doesn't have any raw material costs either. It doesn't even have any conventional manufacturing costs (ie: cost per unit to make), since the program is made once then duplicated electronically. Support costs do rise with the number of users, but far, far less than linearly. Indeed, the second and third users are by far the most expensive ones to add, with things becoming much cheaper after that.
At the end of the day, the cost to write and support a piece of software is essentially a fixed design cost, practically independent of the number of sales. In economic terms, this is called a "marginal cost of zero". To put it another way, there are no economies of scale in software development – the program costs the same to make whether you sell 5 copies or 500 million.
Like any other product, in a healthy free-market economy the force of competition should drive prices down until the pricing reflects the underlying cost structure, plus some minimal reasonable profit margin. The problem for computer software, then, is that if you divide a fixed design cost by a very large number of sales, then no matter how large the design cost was in the first place, the per-unit cost approaches zero.
However it only approaches zero. It never actually reaches zero. It's certainly true that the existing commercial software industry has somehow managed to hide this economy, and commercial software ought to be cheaper than it currently is, especially high-volume software. Nonetheless, it still shouldn't be zero, because that means expecting the programmers to work for no money, even though they're creating something which has value.
The flip side of the only real cost being a design cost, of course, is that if non-commercial open-source programmers choose to give their time and effort voluntarily, without payment, and don't choose to try to sell the result, and since that's the only real cost of developing the software, then the price of that open-source software should be zero.
Unfortunately, that isn't always the case. Today we're seeing an increasing number of "Linux distro companies" emerging based on a business model which effectively tries to sell the open-source software written predominantly by others for free. I believe this is exploitation, plain and simple. It's like going to a soup kitchen, getting some free food, putting it in a nice box and trying to sell it. I fully understand that it is legal, and I understand that in some cases the intentions are good, but I still believe it is unethical. Relevant companies here include Red Hat (RHEL), Novell (SuSE), Xandros and Linspire.
Note that I consider these to be very different from commercial open-source products like MySQL, Qt and Solaris, where the company selling the product clearly wrote the vast majority of the product they sell, and thus absolutely have the right to sell it (or sell service contracts based on it, etc). Commercial Linux distro companies such as Red Hat and Novell cannot reasonably claim to have written more than a small percentage of the product they're selling – therefore they are mostly "cashing in" on work done by others. Such commercial exploitation of open-source software is beginning to loom large as a real problem, turning an increasing number of former open-source programmers away from the movement. Programmers aren't fools, and nobody wants to be exploited.
Sadly, a lot of open-source programmers are still living in a kind of naive denial about this issue. They think the GPL is protecting them from being exploited. Well, take a good look around, guys. There are companies trying to make money out of your open-source software, trying to make money out of the work that you did voluntarily, for no money. Today (mid-2008), Red Hat (Fedora/RHEL) and Novell (SuSE) together make up a substantial portion of the Linux installed base. Those companies are very definitely trying to make money out of Linux, GNU, and open source in general, and therefore out of the unpaid work of many open-source programmers.
Commercial exploitation of open-source software is beginning to loom large as a real problem, turning an increasing number of former open-source programmers away from the movement. Programmers aren't fools, and nobody wants to be exploited.
I know they're legally complying with the GPL. I also concede that they usually give back something to the open-source community, by providing funding for some open-source projects, or paying salaries to a few key programmers. But I still believe unpaid open-source programmers are being exploited by those companies, and that those companies are behaving unethically. Volunteers are building something, unpaid, and those companies are selling it for real money.
Not only that, but the more successful those companies become, the more they try to exert pressure to direct the open-source movement towards their commercial agenda. In Red Hat's case, for example, they fund the GNOME project but not KDE, and have even allegedly mis-configured KDE in the past to make it look bad relative to GNOME. Daniel Robbins, the creator of the non-commercial Gentoo Linux distro, has also pointed out that: "RedHat SRPMs contain a lot of private bug fixes and tweaks that never seem to make it upstream to the original developers".
In recent times, some open-source advocates have finally started to recognize this looming exploitation problem. There was a strong reaction against Red Hat when they asserted that the company, not the community, had ultimate control over the Fedora distro, and similarly when the "enterprise" RHEL variant emerged and the company clearly shifted direction towards it as a more commercial, financially viable product. Voting with their feet, many users and developers have switched away from Fedora to other alternatives. I hope this has served as a good wake-up call and sent a strong message, but only time will tell as to whether Linux and the open-source movement ultimately gets "hijacked" by commercial Linux distro companies. This is a major challenge for the open-source movement. Unfortunately, the legal system can't help here, it's up to the end users and developers to show where their loyalties lie.
Conclusion
Progress is impossible without change, and those who
cannot change their minds cannot change anything.
Open source is not a panacea, not a magic bullet which will fix the software industry. Neither is it an evil underground movement bent on trying to destroy the industry. Like most other things in life, open source is an idea which has both strengths and weaknesses.
I believe it is a mistake to assume that open source will really accelerate big-picture progress. History clearly shows that most of the progress in software has been a handful of big technological leaps – programming languages, the graphical user interface, object-oriented programming, the Internet and World Wide Web. Such major leaps seem to come from a single individual's inspiration, not from a mass of small, incremental steps.
But not every step on the ladder of progress has to be a major stride, and even big leaps are then followed by a series of smaller steps. The GUI we have today is the result of not just the big leap at Xerox PARC and Apple, but also a series of gradual refinements over the following 20 years. Once the leap has been made, and the "leapers" sufficiently rewarded, going open-source definitely can open up opportunities for programmers to build incrementally on each other's work in a way that isn't as easy in the world of commercial, closed-source software.
Thus, I do believe open source has a clear role for maturing technologies, where the remaining improvements are likely to be incremental in nature. With the right licensing model, this can even be done in a commercial context, as demonstrated by the likes of Qt, MySQL and Solaris. It is not easy, but I believe it can be done.
Open source also has a clear role in two other areas. In the world of teaching and academia it can provide a genuine bridge between classroom teaching and real-world practice, an area which is sorely missing from current curriculum. In the world of infrastructure software, open source provides a degree of transparency, dependability, fixability and vendor-independence which simply cannot be matched by closed-source software. These roles are well-established already, and are here to stay.
The biggest problems the open-source movement faces going forward are commercial exploitation by unethical companies trying to "cash in" on other people's work, and the risk of "self implosion by dilution" due to rampant forking and fragmentation. In both cases, it's up to the participants in the open-source movement to keep things on track.
On the forking issue, I think it is the responsibility of all open-source programmers to recognize the problem, make a major effort to avoid further forking, and even reunite competing projects if possible. Let's all try to get along a bit better. "Fusion" should be the buzzword of the day.
On the exploitation front, I believe the open-source community must work actively to prevent exploitation, primarily by simply getting the word out and making sure the public is aware of the no-cost Linux distros and just how little the commercial distros differ from them. There will always be people trying to exploit others, but it's not a lost cause – far from it. We must simply work to keep exploitation in check. In the famous words of Thomas Jefferson: "The price of freedom is eternal vigilance".